写在前面
本文是针对南大蒋炎岩老师 M2: 协程库 的实现总结。如果你也正在做这个 lab,请退出本文,仔细阅读实验文档,多写多调,虽然很难很痛苦,但是真的很有意思。如果你已经完成,欢迎邮件联系讨论相关内容,包括实现思路和相关代码交流。
关于这个实验
从开始阅读文档,到迄今为止完成 64bit 的测试用例(是的,32bit 测试用例还没过),耗费了大量的时间,一点一点摸索。揪着头发在脑子里运行协程,用 GDB 一行一行调试代码,逼急了甚至逐步过汇编代码,无时不让我感慨 coding 和 debug 真难,也真有意思。
2022-07-25 update:
使劲折腾终于用一种无语的方法把 32bit 测试用例通过了,此刻心情复杂。
协程
经过这段时间的 coding,让我大概对 协程 有了一些理解。
线程是 CPU 调度的最小单位,通过系统调用,陷入内核态来完成线程管理和调度;相比较进程而言,调度时上下文更少,因此开销更小一些。然而,抢占式调度终究还要看操作系统的脸色,陷入内核态还是会带来较大开销。
协程,我认为就是一种协作式调度的用户级线程。协作式,也就是由用户来决定调度时机,而不像线程用完时间片就被剥夺 CPU;用户级线程,无需陷入内核态,只要在用户态就可以完成逻辑流的切换。
除此之外,Linux 的线程栈大小默认为 8MB,一般来说用不到这么大;而协程可以自定义栈大小(可以通过修改系统文件来分配线程栈),相比较之下可以起更多的协程。
对于 I/O 密集型任务而言,CPU 用的少,需要更多的进程 or 线程来使用空闲的 CPU,提高利用率。协程相较于进程 or 线程而言,切换上下文开销更少,协程栈更小,就能开更多的协程来执行任务。
libco
libco 定义了相关的 API:
1 | struct co *co_start(const char *name, void (*func)(void *), void *arg); |
co_start()负责创建一个协程,并指定任务函数及参数,创建好的协程不会直接运行,而是返回其指针等待用户指令;co_yield()负责在协程池中随机挑选一个待运行的协程,也就是『协作式调度』的切换函数;co_wait()暂停当前协程,直到指定协程运行结束后再继续当前协程,会在指定协程运行结束后释放其资源,所以用户应当保证初始协程外的每个协程被此函数执行一次。
main 函数所在的协程即为初始协程,通过调用co_yield()和co_wait()切换其他协程,并根据指定的任务函数和参数开始执行,直到函数返回 or 再次切换。
不论还有多少协程未执行结束,只要 mian 函数结束,整个进程即终止。
co 与协程池
定义协程,指定其协程栈大小为STACK_SIZE,64KB。
1 |
|
同时维护一个协程池,以双向链表的形式实现:
1 | // 协程链表结点 |
针对这个协程池,提供一些 API:
1 | /* |
值得一提的是,通过random_num()生成伪随机数,以便随机获取协程池中的协程来调度;而不是简单的在链表上取头结点,仿佛队列一样。
co_start
当调用co_start()时,会在进程的共享内存中创建一个新的状态机,用以表示协程;并在协程创建后,将其压入协程池,方便协程调度时随机执行。主要通过malloc()在堆中为协程申请空间。这个函数实现非常简单,只是创建并初始化协程,然后压入协程池,有以下实现:
依据实验要求删除代码。
co_wait
这里先介绍co_wait()的实现。首先暂停当前协程,然后通过co_yield()调度到目标协程,等目标协程结束后释放其资源并调度回来。
依据实验要求删除代码。
执行co_wait()时,目标协程可能是两种情况:
co->status = CO_DEAD,说明某处调用co_yield()时随机调度到了目标协程,且任务函数执行结束,这时只需要释放协程资源即可;co->status = CO_NEW || co->status = CO_RUNNING,说明目标协程未开始执行 or 执行了但没有执行完成,这时候暂停当前协程,然后通过调用co_yield(),以期调度到目标协程,任务函数执行结束后回到当前逻辑流,让暂停协程继续执行,释放目标协程资源。
可以看到,协程资源释放是通过co_wait()实现的,这就意味着要求用户对所有创建的协程,执行且只执行一次co_wait(),及时释放资源,防止内存泄漏。
co_yield
可以说,libco 的精髓就在于co_yield(),其实现了协程的协作式调度。
在研究其实现前,先研究研究『调度』。进程调度要求保存进程资源、保存上下文环境、通过调度算法选择下一个进程、加载新进程;线程调度要求保存上下文环境并切换线程。
而协程调度与线程调度类似,保存上下文环境然后切换即可。 setjmp.h 提供了相应的接口,用以上下文保存和恢复,这里的上下文对应了co->context。
依据实验要求删除代码。
状态机如下图所示。在调用co_yield()时,首先调用setjmp.h/setjmp()保存当前运行协程current_co的上下文,然后选择下一个协程。我们希望被选择的协程状态为CO_NEWorCO_RUNNING:
CO_NEW表示被选择协程尚未执行,此时需要将其相关参数写入寄存器,然后进入其任务函数;CO_RUNNING表示被选择协程已开始执行,且其任务函数中也调用了co_yield()导致其被切换,此时只需通过setjmp.h/longjmp()重新加载上下文,就会回到任务函数中。
在协程的任务函数中,可能也会中途调用co_yield(),这时重复这个状态切换;也可能彻底执行完成,调整协程状态为CO_DEAD。观察co->waiter是否为空,不为空意味着针对此协程的co_wait()被调用过,通过setjmp.h/longjmp()恢复被暂停协程的上下文,释放协程资源;为空就通过co_yield()继续调度到其他可执行协程。
stack_switch_call
co_yield()中保存和恢复上下文的setjmp.h很有意思,stack_switch_call()也是有趣的函数。这个函数通过扩展内联汇编,手动从co_yield()切换到协程的任务函数中;主要也是这个函数在 x86 和 x86_64 中有不同的实现。
实验文档中提供了示例代码,可以通过 以往的 lab 、 C 内联汇编 和 GCC-Inline-Assembly-HOWTO 来了解扩展内联汇编的相关知识。
通过改写实例代码,stack_switch_call()暂时(2022-07-21)通过了 x86_64 的测试用例。
依据实验要求删除代码。
2022-07-25 update:
32bit 的测试用例无法通过,是因为在call返回后会用到%esp,而此时%esp还指向协程栈中,没有恢复;64bit 不会用到%rsp,所以没有报错。
前面一直知道问题关键点在哪里,想要通过扩展内联来恢复寄存器,但是不论怎么写restore_sp(),汇编中都不会调用相关的扩展内联。今天实在无语,一不做二不休直接把恢复操作写在了stack_switch_call()的call指令后面,于是就成功了。哈哈哈哈什么玩意儿,呸。
依据实验要求删除代码。
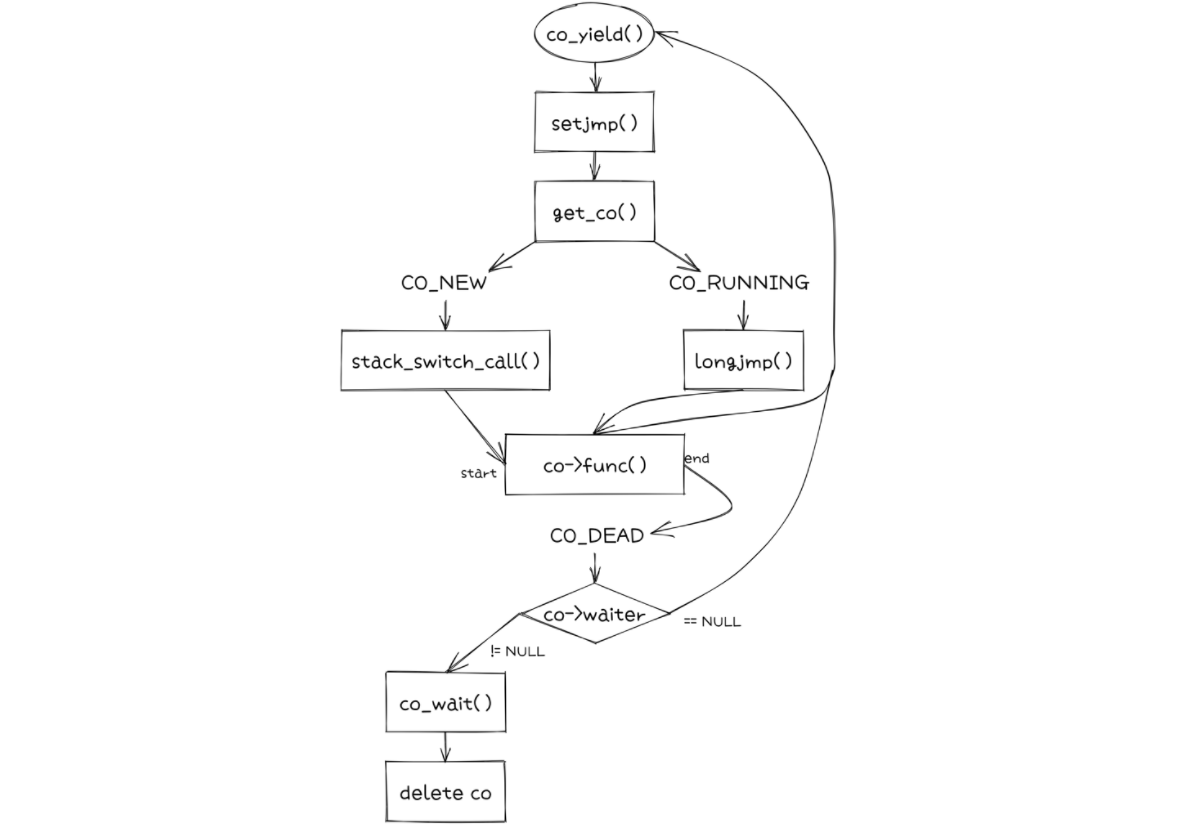
co_ptr->stack通过malloc()申请在堆上,生长方向与内存地址增大方向一致,但是栈是反过来的,所以用来模拟栈时需要反着使用。传入co_ptr->stack + STACK_SIZE表示栈底,并将其写入栈指针;将任务函数参数co_ptr->arg写入相应寄存器 or 栈地址作为第一个也是唯一一个参数;通过call写入返回地址并进入任务函数co_ptr->func。
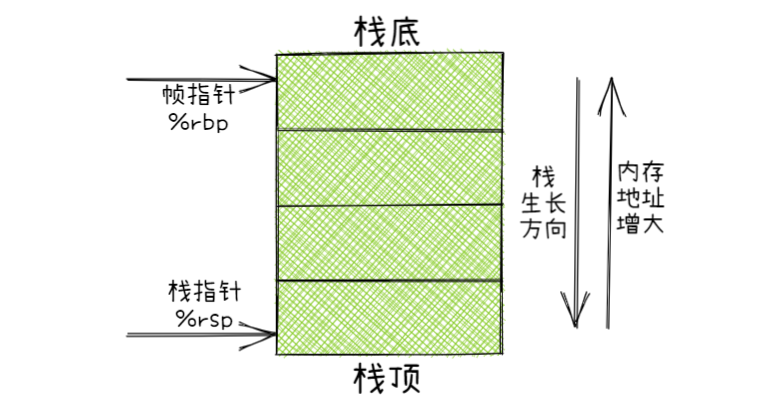
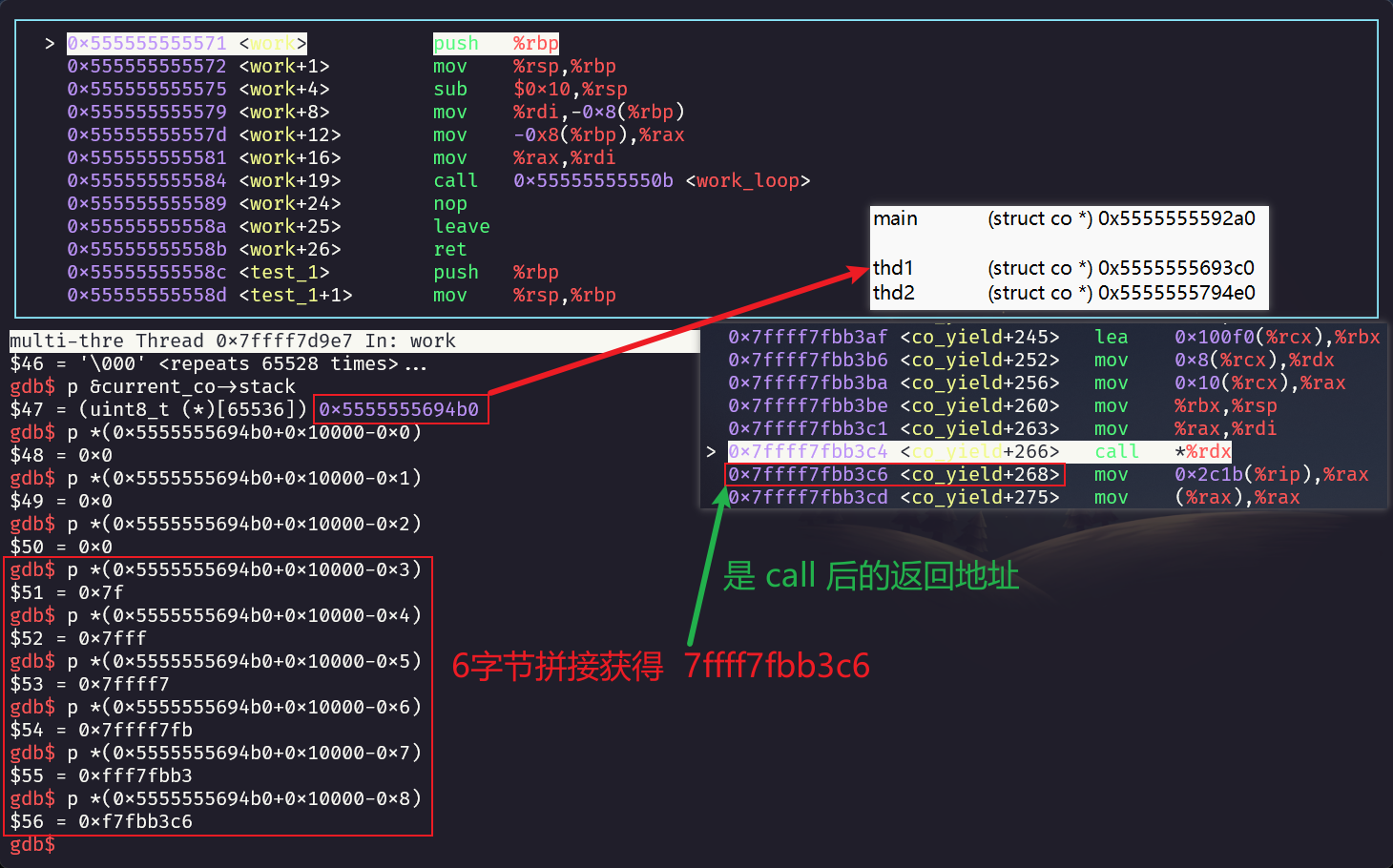
通过 GDB 可以看到call后的返回地址与co_ptr->stack + STACK_SIZE -0x8的值相等,总共占 6 个内存空间共 6 字节。