进程与线程
进程:是一个正在执行程序的实例,包括有程序计数器、寄存器和变量的当前值
程序执行之后,从磁盘的二进制文件,到内存、寄存器、堆栈指令等等所用到的相关设备状态的一个集合,是数据和状态综合的动态表现
线程:一个进程含有一个至多个线程,线程通过使用进程的资源来执行任务
进程是资源分配的最小单位,线程是 CPU 调度的最小单位
进程之间的地址空间和资源相互独立;同一进程下的线程共享进程的地址空间和资源
一个进程崩溃后,对其他进程不会产生影响;但是一个线程崩溃后,会对同一进程下的其他线程产生影响,导致整个进程崩溃
PCB
操作系统利用进程控制块(process control block,PCB)来描述进程。Linux 中使用 task_struct 数据结构定义 PCB,包含进程所有的信息
PCB 是进程存在的唯一标识,包含进程描述信息、进程控制管理信息、资源分配清单和 CPU 相关信息
- 进程描述信息:进程标识符、用户标识符
- 进程控制管理信息:进程当前状态、进程优先级
- 资源分配清单:地址空间、打开的文件、使用的 I/O 设备
通过链表的方式将 PCB 组织起来,又可以分为就绪队列、阻塞队列等
TCB
线程通过线程控制块(TCP)描述线程,类似于 PCB,记录线程状态信息
进程有哪些资源?
- CPU 上下文:
- 寄存器:CPU 中内置的容量小、速度极快的硬件
- 程序计数器:记录 CPU 正在执行的指令,或者下一条指令的位置
- 地址空间:
- 栈区:由编译器自动分配释放、存放函数的参数值、局部变量的值等
- 堆区:由人工为对象分配和释放内存
- 动态链接库:如果这个程序是动态链接生成的,那么进程的地址空间中有一部分包含的是动态链接库
- 文件:如果程序在运行过程中打开文件,文件信息保存在进程的地址空间中
- 代码区:存放编译后的可执行文件中的机器指令
- 数据区:存放全局变量(函数外的全局变量,函数内由
static修饰的静态变量)
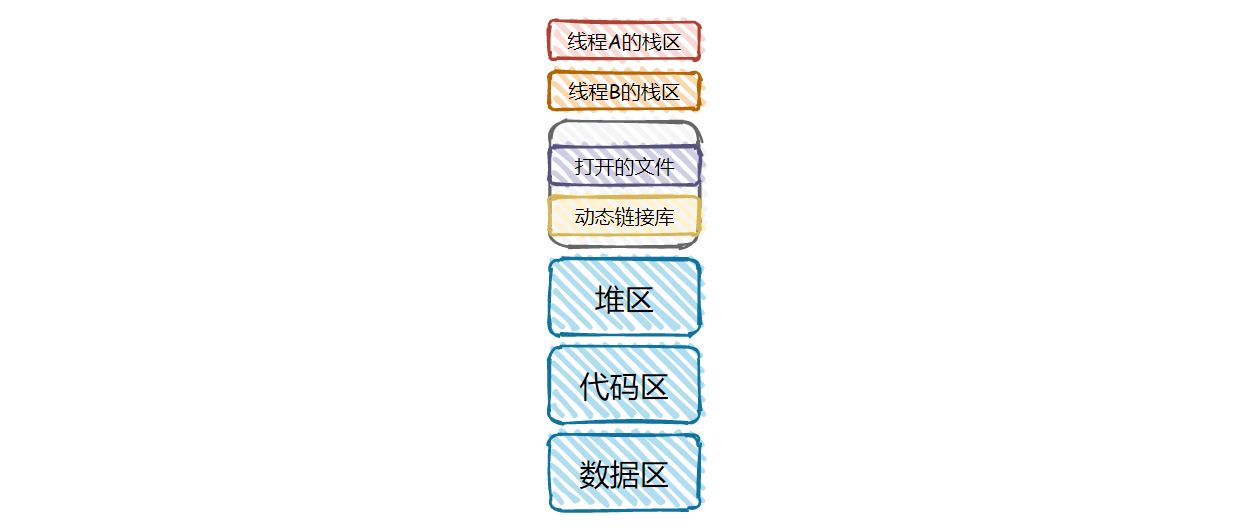
线程独占和共享哪些资源?
首先,CPU 执行指令的信息都是保存在寄存器和程序计数器中的。因此,每个线程独占寄存器和程序计数器
其次,线程执行程序时,由编译器自动分配释放、产生的局部变量,都存储在栈区中。因此,每个线程在栈区中有自己独占的一个栈,存放私有数据
则堆区、动态链接库(如果存在)、文件(如果打开过)、代码区和数据区由线程共享。线程可用通过指针记录的地址,访问堆区中的数据;所有线程共享动态链接库
但是,栈区并不是严格意义上由线程独占。某个线程如果有其他线程操作自己栈区的指针,那这个线程可以通过这个指针对其他线程的栈区进行操作,修改其他线程的私有数据
什么时候发生进程调度?
- 当前进程任务完成,主动终止
- 当前进程任务未完成,时间片耗尽,被剥夺 CPU 并放入就绪队列
- 有更高优先级的进程到达,被抢占
- 当前进程主动阻塞,如 I/O 请求,被剥夺 CPU 并放入阻塞队列
- 当前进程发生 I/O 中断,被阻塞且等待该中断的进程从阻塞态转变为就绪态;可以立即被调度运行,也可以等待当前进程结束再运行
- 创建新进程之后,需要决定运行父进程还是子进程。
fork()后两种进程处于就绪状态,等待分配 CPU
进程调度时,内核做了什么,CPU 做了什么?
进程由内核来管理,进程的切换只能发生在内核态
进程切换到另一个进程:
- 将进程的上下文保存到 PCB 中,比如 CPU 寄存器的内容和程序计数器记录的指令位置,保存到 PCB 中;将当前进程按照需求放入就绪队列或阻塞队列等
- 通进程调度算法选择一个新进程,并更新 PCB 的进程控制管理信息
- 将新进程的上下文(PCB 中记录的寄存器内容和指令位置)加载到 CPU 的寄存器和程序计数器中,根据 PCB 记录的地址空间,找到资源,并跳转到程序计数器所值的位置,开始运行程序
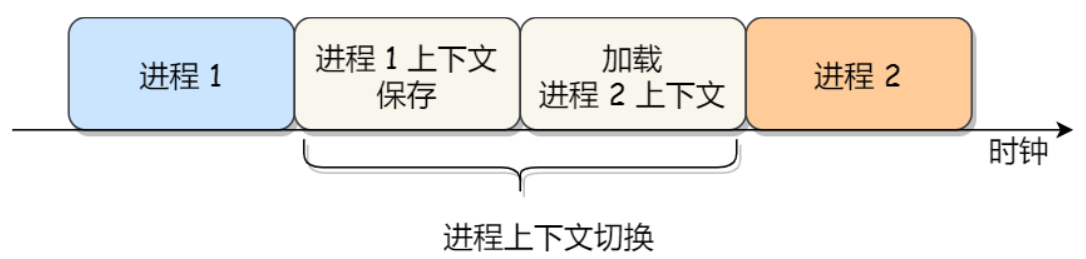
总结:从用户态切换到内核态后,内核保存用户态资源(地址空间等),保存 CPU 上下文;根据调度算法选出的进程,将 CPU 上下文加载到 CPU 中,并刷新进程的用户态资源
线程调度时,内核做了什么,CPU 做了什么?
通过进程是资源分配的最小单位,线程是 CPU 调度的最小单位,可以知道,实际上执行任务的是线程,即线程调度时保存的是当前运行的线程的 CPU 上下文
线程共享进程的地址空间,因此切换上下文时不需要修改,只需要修改 CPU 上下文
不同进程下的线程调度:等同于进程调度
同一进程下的线程调度:
- 保存当前线程的寄存器、程序计数器和栈区
- 根据调度算法选择一个新线程
- 将新线程的寄存器、程序计数器和栈区进行加载,开始运行
内核做了什么,需要看是什么线程,CPU 只是单纯的切换 CPU 上下文
用户级线程(多对一模式)
用户级线程在管理时,内核看不见所谓的线程,因此内核将资源(时间片、CPU)划拨给进程,由进程来管理线程,TCB 放在进程中,管理包括线程的创建、终止、同步和调度等操作
我理解的多对一模式:进程是资源分配的最小单位,线程是 CPU 调度的最小单位,且操作系统可以看见内核级线程,看不见用户级线程,那归根结底,CPU 被分配给的内核级线程。这个多对一模式,就是把用户态下的一个进程(包含多个用户级线程),对应给一个内核级线程。即多个用户级线程共享一个 CPU core,就产生了优点和缺点
- 用户级线程可以在不支持线程的操作系统上实现
- 用户级线程在调度时,不需要用户态和内核态的切换,不需要切换上下文,不需要对内存高速缓存进行刷新,所以调度速度快
- 线程可以可以自定义调度算法,切换到其他线程
- 用户级线程只能自己主动放弃 CPU,才可以由其他的用户级线程运行
调用库过程thread_exit退出;调用rhread_join阻塞一个线程等待另一个特定线程退出;调用thread_yield使线程自动放弃 CPU 从而让另一个线程运行 - 一个线程崩溃时,会影响同一进程下的所有线程,导致进程崩溃
当这个用户级线程阻塞时,由于内核看不见用户级线程,它会认为整个进程阻塞,将进程调入阻塞队列,导致这个进程下的其他线程无法运行
比如进行系统调用,或者线程发生缺页中断引发阻塞
内核级线程(一对一模型)
内核级线程由操作系统管理,线程对应的 TCB 自然是放在内核里的,这样线程的创建、终止和管理都是由操作系统负责
我理解的一对一模型:这里的一对一,就是一个用户级线程对应一个内核级线程(也就是用户空间的一个进程拥有多个 CPU core)
- 内核级线程由内核管理,当线程阻塞时,同一进程下的其他线程不会被阻塞
- 当一个线程被阻塞时,内核选取同一进程下的另一个就绪线程或者不同进程下的就绪线程来运行
- 内核维护 PCB 和 TCB,通过系统调用实现对线程的管理,系统开销比较大
混合实现(多对多模型)
将用户级线程与某些或者全部内核级线程多路复用起来,就是说,用户空间的一个进程(有多个用户级线程),对应多个内核级线程
- 切换时可以实现同一个内核级线程下的多个用户级线程在用户态切换,开销小
- 某一个用户级线程阻塞时,只会影响这个内核级线程对应的多个用户级线程,不会影响到同一个进程下其他内核级线程对应的用户级线程
有哪些调度算法?
- 先来先服务调度算法
- 短作业优先调度算法
- 最短剩余时间优先算法
- 高响应比优先调度算法
- 时间片轮转调度算法
- 优先级调度算法
- 多级反馈队列调度算法
进程如何通信?
详情见 多进程编程 | xStack
进程与线程的简单比喻
进程 = 火车,线程 = 车厢
- 线程在进程下行进(单纯的车厢无法运行)
- 一个进程可以包含多个线程(一辆火车可以有多个车厢)
- 不同进程间数据很难共享(一辆火车上的乘客很难换到另外一辆火车,比如站点换乘)
- 同一进程下不同线程间数据很易共享(A 车厢换到 B 车厢很容易)
- 进程要比线程消耗更多的计算机资源(采用多列火车相比多个车厢更耗资源)
- 进程间不会相互影响,一个线程挂掉将导致整个进程挂掉(一列火车不会影响到另外一列火车,但是如果一列火车上中间的一节车厢着火了,将影响到所有车厢)
- 进程可以拓展到多机,进程最多适合多核(不同火车可以开在多个轨道上,同一火车的车厢不能在行进的不同的轨道上)
- 进程使用的内存地址可以上锁,即一个线程使用某些共享内存时,其他线程必须等它结束,才能使用这一块内存。(比如火车上的洗手间)-『互斥锁』
- 进程使用的内存地址可以限定使用量(比如火车上的餐厅,最多只允许多少人进入,如果满了需要在门口等,等有人出来了才能进去)-『信号量』
作者:biaodianfu
链接:进程与线程的区别是什么?
来源:知乎